Les termes "Intelligence Artificielle" peuvent faire référence à plusieurs technologies et techniques très différentes les unes des autres mais qui ont pour point commun d'essayer de reproduire l'intelligence humaine.
La méthode la plus prolifique pendant les deux dernières décennies a été l'Apprentissage Automatique (Machine Learning), qui est une méthode statistique permettant de donner de grands volumes de données à un algorithme qui est ensuite capable d'extrapoler les informations pour trouver une solution à un problème.
L'apprentissage machine est fondamentalement différent de ce qui était utilisé avant et notamment du Système expert. En effet, ce dernier consiste à établir un ensemble de règles précises et explicites pour prendre une série d'actions, ce qui est une très bonne approche quand il s'agit de résoudre des problèmes relativement simples avec des règles claires et faciles à formuler, mais se révèle très limitée quand ce n'est pas le cas. La force de l'apprentissage automatique réside dans le fait que les règles qui permettent de répondre au problème ne doivent pas être explicitées par l'informaticien qui programme le logiciel, mais elles sont comprises par le logiciel pendant la phase d'apprentissage. Cela permet d'appréhender des sujets plus complexes, comme par exemple le langage, ou le raisonnement: en effet, ces concepts ne sont pas faciles à expliquer ou à enseigner à quelqu'un en essayant de les résumer à un ensemble de règles. D'ailleurs, nous humains ne les apprenons pas comme cela non plus: ces capacités nous sont en partie acquises et en partie, nous les apprenons au contact d'autres êtres humains, par mimétisme.
NOTE: Les logiciels utilisés pour le Machine Learning sont souvent des Réseaux de Neurones (Artificial Neural Network)
Un des premiers cas où le Machine Learning a été appliqué avec succès est la Vision par ordinateur. Reconnaître un objet comme une lampe, un téléphone ou un animal sur une image est une tâche très simple pour un humain mais difficile à formuler par des règles qui soient compréhensibles par une machine. C'est donc un problème tout indiqué pour l'usage du Machine Learning.
Bien que le Machine Learning (ML) permet d'accéder à des problèmes plus complexes comme la classification d'objets, le fait de ne pas fonctionner avec des règles explicites est aussi une faiblesse et le rend moins fiable et moins déterministe. Un même logiciel ou Réseau de Neurones peut classifier une même partie d'une image comme un chien, un chat ou en fonction des données qui lui sont présentées durant la phase d'entraînement. Un réseau de neurones est hautement probabiliste et ne permet pas de donner une réponse avec certitude mais seulement avec un niveau de confiance qui peut être plus ou moins élevé. Dans l'image ci-dessous, par exemple, un réseau de neurones est capable de reconnaître différents objets typiques des rues d'une ville, mais rarement avec un score de confiance de 100%

Le cas le plus connu d'utilisation de l'IA en 2024 est évidemment l'IA générative — et, oui, il s'agit bien de Machine Learning. Les logiciels qui génèrent du texte sont appelés des LLMs pour Large Language Model (ou Grand Modèle de Langage). Leur fonctionnement est très complexe — même pour un réseau de neurones — et nous n'entrerons pas plus en détail quant à son fonctionnement ici. Cependant, il est bon de noter quel est le but des LLMs et comment ils sont entraînés. Cela permet de savoir quels sont leurs forces et comment les utiliser.
Un LLM est un Réseau de Neurones très polyvalent et n'est pas entraîné à une seule tâche (comme un classificateur de sentiments ou un classificateur d'images par exemple). L'objectif d'un LLM est de prédire la séquence la plus probable qui suit une séquence donnée en paramètre. Ainsi, quand nous posons une question à ChatGPT, nous lui donnons en paramètre une séquence de mots et sa réponse est la séquence de mots qu'il produit en retour.
Comme tout est probabilité dans la génération de texte, on ne peut jamais être vraiment sûr à 100% que la réponse d'un LLM est vraie. Elle est juste probable. Les LLMs produisent d'ailleurs notoirement des hallucinations de temps à autre.
Mais alors si les LLMs ne sont pas fiables, comment peut-on faire confiance à l'IA ?
Baser une IA juridique — ou plus généralement une IA qui doit fournir des informations de qualité — uniquement sur des LLMs n'est pas une bonne idée. Non seulement ceux-ci ne sont pas corrects dans tous les cas, mais leur entraînement est très opaque, donc même quand ils le sont, ils sont souvent incapables de citer leurs sources. En d'autres termes, ils possèdent de grandes connaissances, mais ils ne savant pas dire d'où viennent ces connaissances.
Pour palier à ces problèmes, il ne faut pas se fier aux connaissances des LLMs mais dissocier leur capacité de raisonner — qui, elle, est impressionnante — de leur capacité à retrouver l'information. Il faudrait en somme qu'il y ait deux entités au lieu d'un LLM seul: une qui comprend la requête de l'utilisateur et qui retrouve les bonnes sources et une autre qui raisonne à partir de ces sources pour créer une réponse.
Un LLM fait très bien la seconde partie. La pièce manquante pour accomplir la première s'appelle la Recherche Sémantique.
Cette Recherche Sémantique se base sur une autre technique de ML qui est le Plongement lexical. Cette dernière permet d'accéder à une représentation abstraite où les concepts sont symbolisé par des vecteurs — que l'on peut voir aussi comme des points sur un espace de grande dimensions.
Un exemple simple et souvent utilisé pour illustrer le concept de plongement lexical est le suivant:
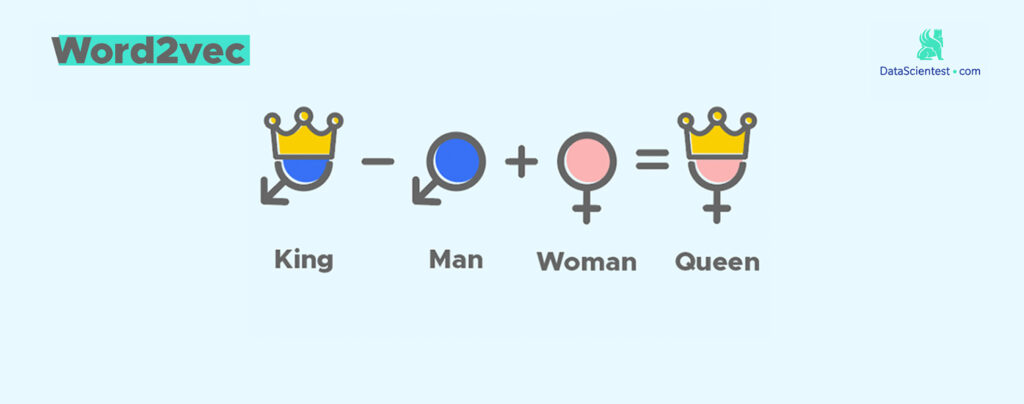
Considérons qu'au lieu de représenter des concepts, on représente de simples mots par des vecteurs. Dans cet espace abstrait où vivent les vecteurs, on peut faire des opérations classiques comme l'addition ou la soustraction. Ainsi, il es naturel de constater que le fait d'ajouter les vecteurs "Roi" et "Femme" donne le vecteur "Reine".
Pour effectuer la Recherche Sémantique, on vectorise tout d'abord tous les textes sur lesquels on veut effectuer la recherche. Ensuite, il est possible de poser une question à l'ensemble de ces textes en vectorisant également la dite question: pour cela, il faut simplement trouver les textes qui ont des vecteurs proches de celui de la question. Cette étape est réalisée assez simplement en calculant la distance entre le vecteur requête et tous les autres vecteurs de l'espace.
L'image ci-dessous montre comment des concepts similaires sont représentés par des vecteurs proches les uns des autres après plongement lexical.

La Recherche Sémantique est plus subtile qu'une simple de recherche par mot-clé. Elle permet d'avoir des résultats plus pertinents en posant des questions en langage naturel.
Maintenant que nous avons vu comment accéder aux informations, nous savons comment Hammurabi fait pour répondre aux questions à partir de données réelles, en minimisant — voire en supprimant — les hallucinations : c'est le fruit de la combinaison entre la Recherche Sémantique, qui trouve les textes pertinents, et un LLM qui les agrège, les évalue et les reformule pour donner une réponse synthétique.
graph TD
title[Fonctionnement de la Recherche Sémantique et d'un LLM ensemble]
A[Question de l'utilisateur] -->|Entrée| B[Orchestrateur]
B -->|Récupération des données| C[Base de données]
C -->|Documents importants| B
B -->|Documents importants| D[LLM]
D -->|Réponse synthétique| E[Utilisateur]
style A fill:#f9f,stroke:#333,stroke-width:4px;
style B fill:#ff9,stroke:#333,stroke-width:4px;
style C fill:#9f9,stroke:#333,stroke-width:4px;
style D fill:#9ff,stroke:#333,stroke-width:4px;
style E fill:#f99,stroke:#333,stroke-width:4px;
Bien que plusieurs réseaux de neurones sont en jeu au sein de ce procédé, la Recherche Sémantique est un procédé qui n'en utilise pas et donc ne fait pas appel à l'apprentissage automatique. Cela signifie que cette étape cruciale à la génération de la réponse est assez peu soumise à l'aléatoire. Ce point est très important car c'est ce qui permet d'apporter un peu de déterminisme et de vérifiabilité dans un LLM, qui, autrement en manque cruellement.
C'est cette combinaison de plusieurs IA qui fait la force d'Hammurabi.
